

 Congrats!
Congrats!
Our paper, MoDA, wins Best Paper Award at CVPR Workshop on Learning with Limited Labelled Data for Image and Video Understanding (L3D-IVU).
MoDA: Leveraging Motion Priors from Videos for Advancing Unsupervised Domain Adaptation in Semantic Segmentation
Fei Pan*, Xu Yin*, Seokju Lee, Axi Niu, Sungeui Yoon, In So Kweon (* equal contribution)
CVPR Workshop on Learning with Limited Labelled Data for Image and Video Understanding (CVPRw), Jun 2024 Best Paper Award

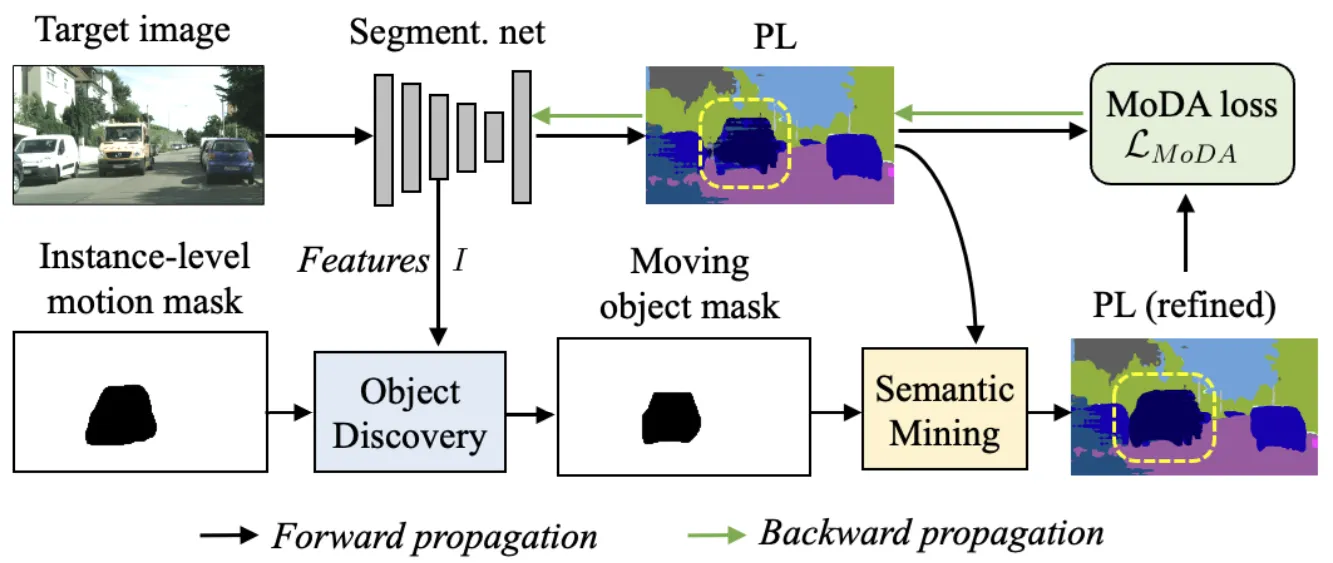
We present an innovative unsupervised domain adaptation (UDA) framework for semantic segmentation, particularly addressing scenarios with unlabeled video frames in the target domain. Our framework, called Motion-guided Domain Adaptive semantic segmentation (MoDA), leverages recent advancements in self-supervised learning of object motion from videos. MoDA includes an object discovery module that localizes and segments moving objects using motion information and a semantic mining module that refines pseudo labels based on these object masks. These refined pseudo labels are then used in a self-training loop to bridge the cross-domain gap. Experimental results demonstrate that MoDA effectively uses object motion for domain alignment, surpassing traditional optical flow methods and complementing existing state-of-the-art UDA approaches.